LLMs Explained - Part 4 - seq2seq
Overview
In the previous parts, we covered how to tokenize the data, create word embeddings for training a large language model (LLM) & the fundamentals of RNNs. Now let’s look into the model architecture for our translation model which builds on the RNNs and combines it with the powerful encoder-decoder architecture.
We will go back to our use case for this language model which is translation! In this article, we will look at how this problem was attempted using seq2seq model architecture.
What is seq2seq?
The language model is tasked with taking a string as input, say “Let’s go!” and translate it into French, “Allons-y!”. 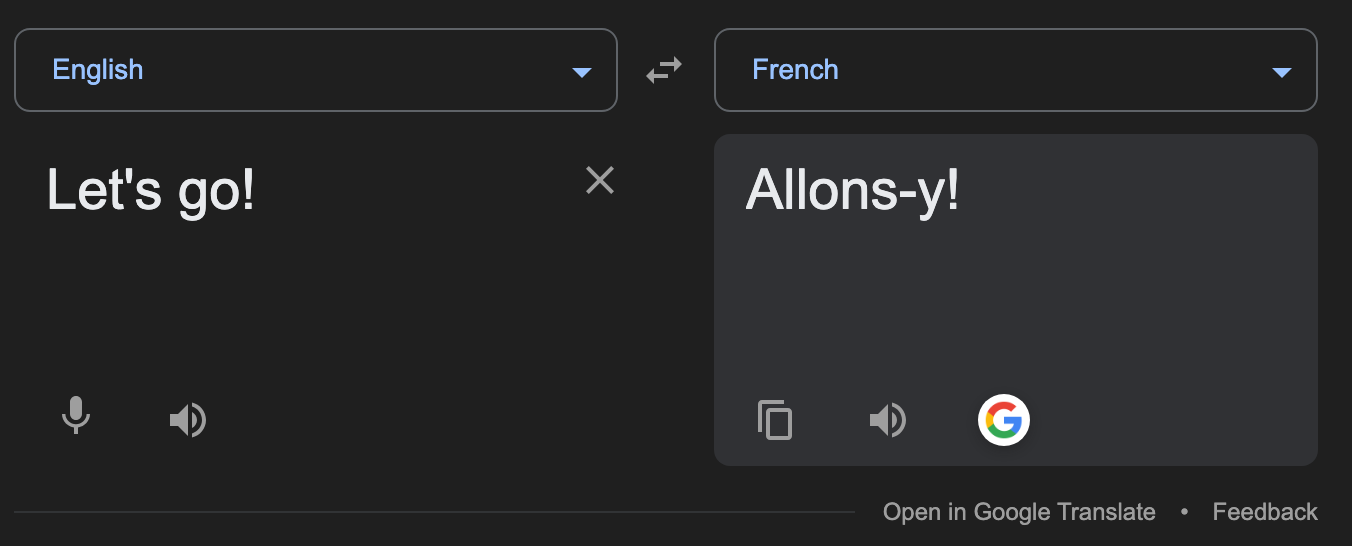
This problem statement falls under seq2seq which is a family of machine learning approaches used for natural language processing. Applications include language translation, image captioning, conversational models, and text summarization.
The seq2seq approach was first made popular by the paper Sequence to Sequence Learning with Neural Networks which we uses stacked LSTM units in an encoder-decoder architecture. We will cover this in detail as part of this article starting with the encoder-decoder architecture.
Encoder-Decoder Architecture
Encoder-decoder architecture is a fundamental framework used in various fields, including natural language processing, image recognition, and speech synthesis. At its core, this architecture involves two connected neural networks: an encoder and a decoder. The encoder processes the input data and transforms it into a different representation, which is subsequently decoded by the decoder to produce the desired output.
The intuition is quite simple. Input like audio, sentences and images may not be easy for the model to understand the way humans do. So if the model is able to convert it to a format where it can understand better (encoder) then it can manipulate the sentences/images/audio as desired (decoder). Essentially, the encoder converts all the input data into a (latent) representation which it can make sense of and the decoder converts the (latent) representation to human understandable format. The best part is that the model decides hows to represent and manipulate the data itself as part of the training!!
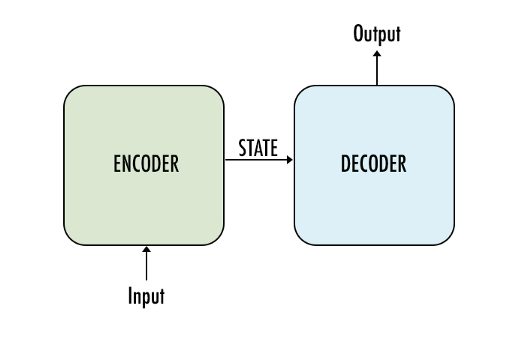
Encoder: The encoder processes the input sequence (e.g., a sentence in the source language) and compresses it into a fixed-length context vector (also known as the thought vector). This vector aims to capture the semantic meaning of the entire input sequence.
Decoder: The decoder takes the context vector produced by the encoder and generates the output sequence (e.g., the translated sentence in the target language). The output is typically generated one token at a time.
Latent State: This is a lower dimensional space which represents all the information in a compressed format. This may seem meaningless to use by the model knows exactly what it represents. For example: if you pass an image of an owl to an encoder-decoder model, the encoder outputs a context vector in say 50 dimensions like
[0.414, 1.21, ....].
The encoder-decoder architecture has wide applications beyond machine translation like computer vision, anomaly detection, dimensionality reduction etc.
One of the simplest implementations of encoder-decoder architecture is the autoencoder. An autoencoder is a type of artificial neural network used to learn efficient codings of unlabeled data (unsupervised learning). An autoencoder learns two functions: an encoding function that transforms the input data, and a decoding function that recreates the input data from the encoded representation. The autoencoder learns an efficient representation (encoding) for a set of data, typically for dimensionality reduction.
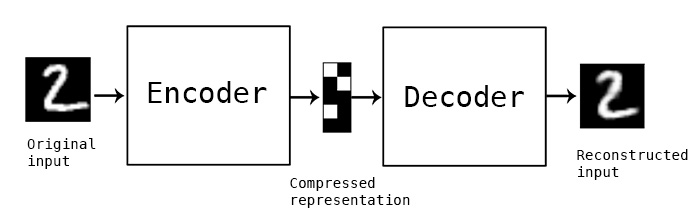
An autoencoder has the decoder structure as the exact mirror of the encoder as you can see in this code snippet below:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
class AE(torch.nn.Module):
def __init__(self):
super().__init__()
# Building an linear encoder with Linear
# layer followed by Relu activation function
# 784 ==> 9
self.encoder = torch.nn.Sequential(
torch.nn.Linear(28 * 28, 128),
torch.nn.ReLU(),
torch.nn.Linear(128, 64),
torch.nn.ReLU(),
torch.nn.Linear(64, 36),
torch.nn.ReLU(),
torch.nn.Linear(36, 18),
torch.nn.ReLU(),
torch.nn.Linear(18, 9)
)
# Building an linear decoder with Linear
# layer followed by Relu activation function
# The Sigmoid activation function
# outputs the value between 0 and 1
# 9 ==> 784
self.decoder = torch.nn.Sequential(
torch.nn.Linear(9, 18),
torch.nn.ReLU(),
torch.nn.Linear(18, 36),
torch.nn.ReLU(),
torch.nn.Linear(36, 64),
torch.nn.ReLU(),
torch.nn.Linear(64, 128),
torch.nn.ReLU(),
torch.nn.Linear(128, 28 * 28),
torch.nn.Sigmoid()
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
seq2seq with LSTMs
Machine translation involves a few challenging problems for the model to address:
- Represent input sequences in a lower dimensional and manipulate that to generate the output sequence
- Process & generate sequences of multiple lengths
- Learn context and grammar of the input and target language
We know that #1 can be addressed via the encoder-decoder architecture but how do we process sequences of multiple lengths and transform the sequence based on the grammar & context of the source & target language? As we have seen in the previous post, RNNs are cut out exactly for this purpose. We can pass the word embeddings as an input to the RNN and unroll it for each word. Using LSTMs we can propagate both the short-term and long-term memory of the sequence.
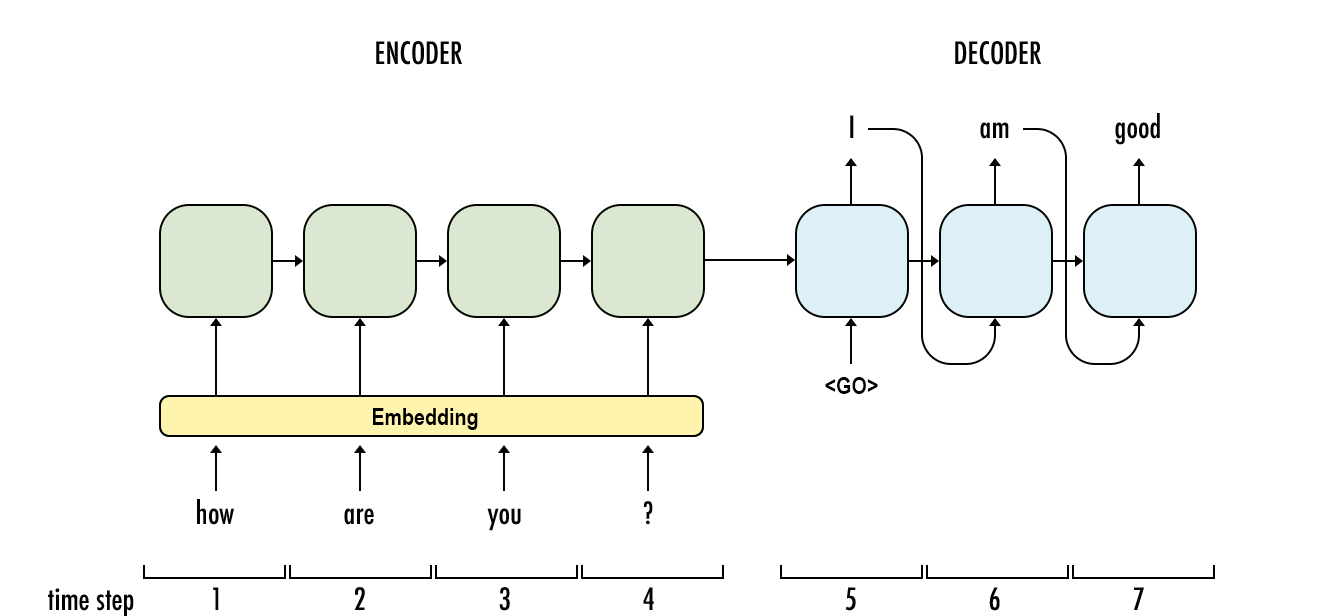
The initial seq2seq architecture essentially combines the encoder-decoder architecture with LSTM units as shown below.
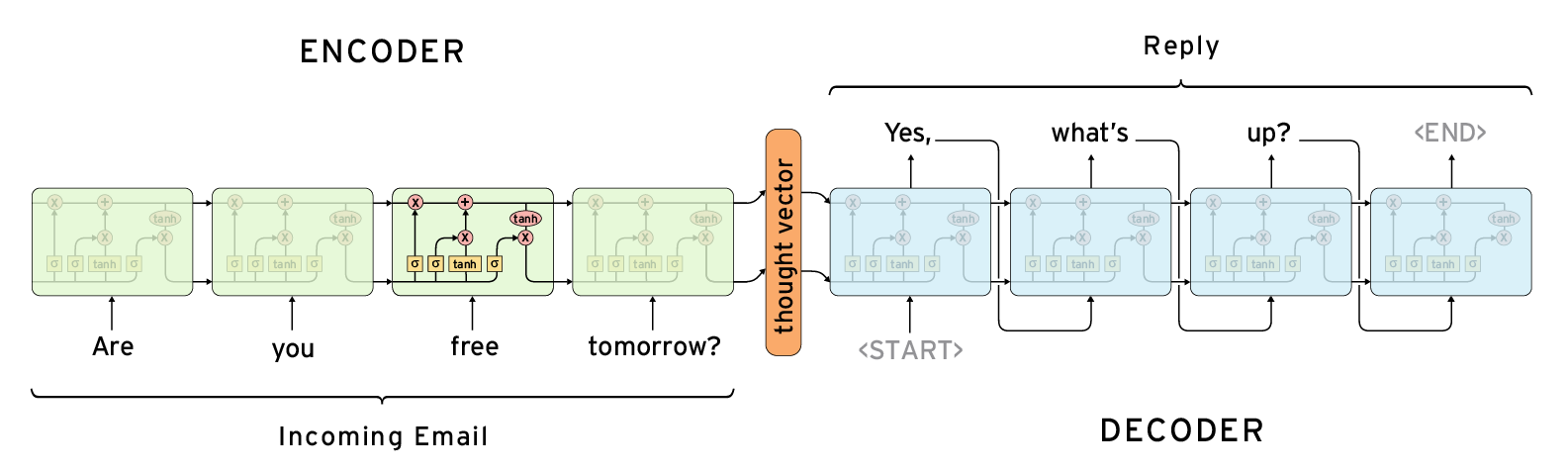
The LSTM unit allows the encoder to capture long semantics & context. The encoder condenses the input sequence into a thought/latent vector while retaining the semantics & context information. This thought vector is unrolled using another LSTM unit to generate the output sequence. To model more complex relations we can stack multiple LSTM units as shown here.
To understand better let’s look at an example of how “Let’s go” would be translated using a seq2seq model:
- Input sequence: “let’s go”
- Tokenize & Embedding: “let’s”, “go” ->
[[0.31, 0.35, ..], [0.86, 0.73, ..]] - Encode: First, “let’s” is passed to the encoder’s LSTM unit which outputs $c_1$ and $h1$ (long-term and short-term output respectively)
- Unroll: Next, we unroll and concatenate $c_1$ & “go” embedding as input to the same encoder LSTM unit to generate $c_2$ and $h_2$ (thought/latent vectors)
- Decode: Now we start the decoder phase passing $c_2$ and $h_2$ as input to the decoder LSTM unit to generate $\tilde{c_1}$ and $\tilde{h_1}$ (long-term and output word embedding resp)
- $\tilde{h_1}$ word embedding will be decoded to the word
Allons - The decoding of the $\tilde{h_1}$ vectors happens by connecting it to a fully-connected MLP with a softmax layer as output
- The number of values for the softmax layer would be as many as the vocabulary itself for tokenization (as high as 160k tokens as per the paper)
- The softmax would select the tokens to be activated which will be decoded to generate the translated word of the sequence
- $\tilde{h_1}$ word embedding will be decoded to the word
- Unroll: We continue to unroll the decoder LSTM unit by passing $\tilde{h_2}$ & $\tilde{c_2}$ as input which return the embedding for
y - At last w pass $\tilde{h_2}$ & $\tilde{c_2}$ as input back to the decoder LSTM unit which return the embedding for
<END>as output- This terminates the sequence generation with the final output being
Allons-y!
- This terminates the sequence generation with the final output being
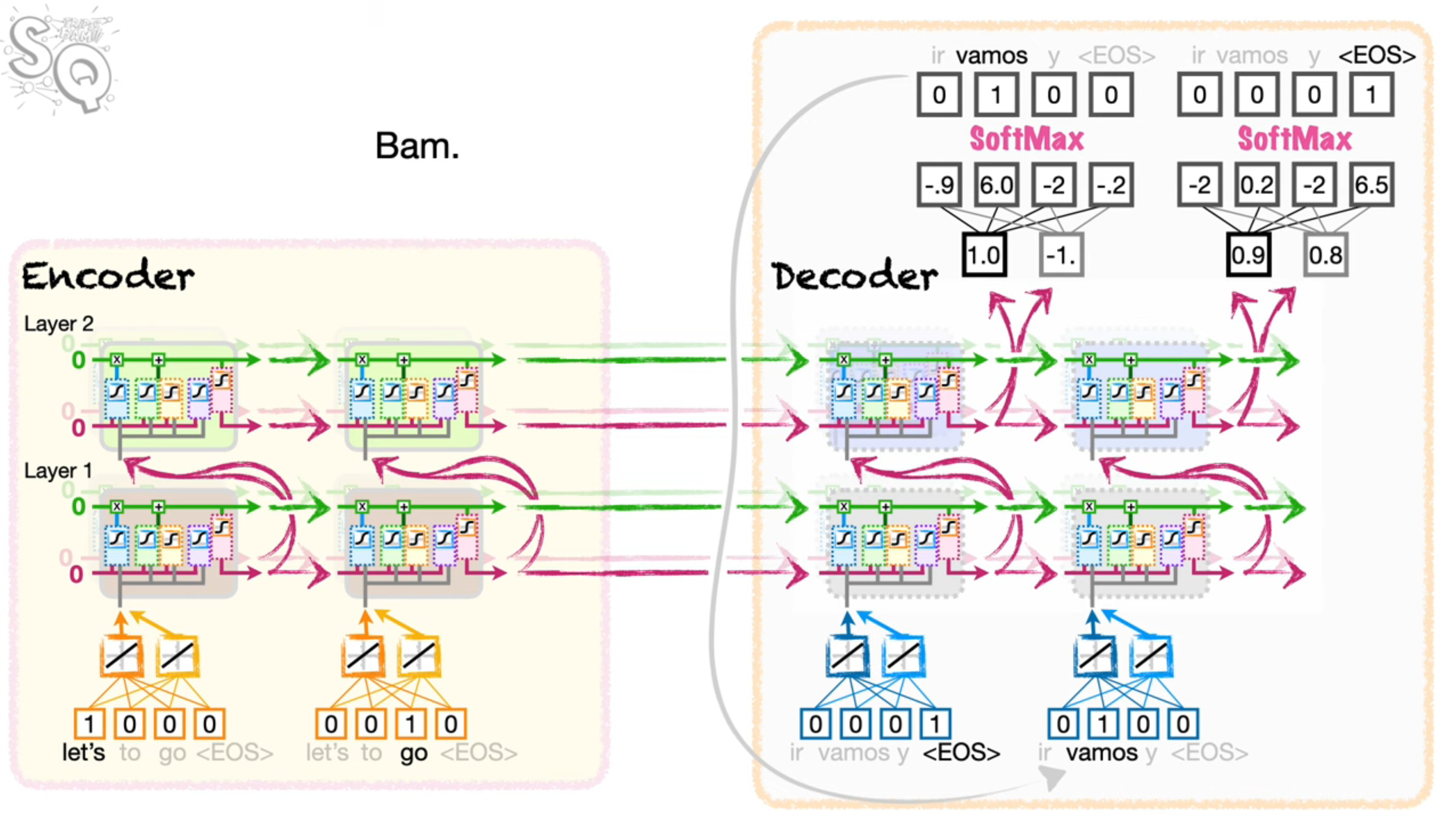
In reality, the scale of these models are significantly larger! As per the paper for example:
- The input vocabulary used 160,000 tokens
- It used 100 embedding values to represent a token
- Instead of the 2 layers with 2 LSTM units, the encoder used 4 layers with 1000 LSTM units per layer
- This also means the output layer had 1000 outputs from the decoder LSTM unit
- The softmax output had 80,000 outputs to match the size of the vocabulary
Further Readings
- https://d2l.ai/chapter_recurrent-modern/encoder-decoder.html
- https://d2l.ai/chapter_recurrent-modern/seq2seq.html
- https://www.youtube.com/watch?v=L8HKweZIOmg&list=PLblh5JKOoLUIxGDQs4LFFD–41Vzf-ME1&index=20&ab_channel=StatQuestwithJoshStarmer
- https://arxiv.org/pdf/1409.3215
- https://github.com/bentrevett/pytorch-seq2seq/tree/rewrite
- https://en.wikipedia.org/wiki/Autoencoder#:~:text=An%20autoencoder%20is%20a%20type,data%20from%20the%20encoded%20representation
- https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html
- ChatGPT