Flash, Fused and Fast Attention

A change of approach
From ~2020 onward, the focus of attention research subtly shifted:
Before: Researchers were asking, “How can we change the algorithm to avoid quadratic cost?”
This gave rise to Sparse Attention, Linformer, Performer, etc.—all mathematically clever but often impractical or brittle in real-world deployment.Then came the pivot: “Wait… what if we just make the existing attention stupid fast and memory-efficient using low-level tricks?”
This is where engineering took over:
- CUDA-level fusion (compute + softmax + dropout + matmul in one pass)
- Avoiding memory bottlenecks (no materializing attention matrix)
- Tiling, pipelining, register-level hacks
- Hardware-specific tuning (e.g., tensor cores, shared memory optimizations)
If you want to know why attention performance optimization is importance, I’ve coverted it in detail over here.
If you want to know more about GPUs, kernels and an introduction to all the low-level stuff, you can check out this post. But dropping a quick relevant refresher below right from the flash attention papers.
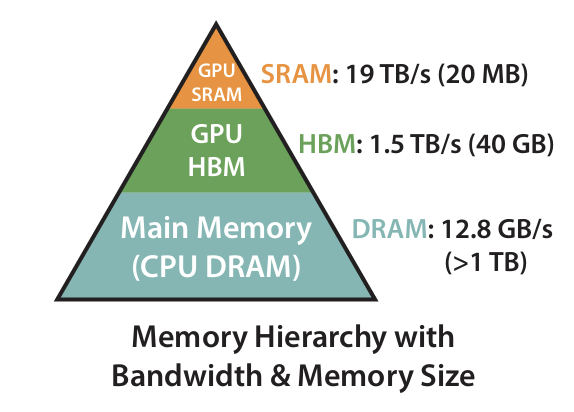
Memory hierarchy
- Most modern GPUs contain specialized units to accelerate matrix multiply in low-precision (e.g., Tensor Cores on Nvidia GPUs for FP16/BF16 matrix multiply).
- The memory hierarchy comprise of high bandwidth memory (HBM), and on-chip SRAM (aka shared memory).
- As an example, the A100 GPU has 40-80GB of high bandwidth memory (HBM) with bandwidth 1.5-2.0TB/s and 192KB of on-chip SRAM per each of 108 streaming multiprocessors with bandwidth estimated around 19TB/s.
- As the L2 cache is not directly controllable by the programmer, we focus on the HBM and SRAM for the purpose of this discussion.
Thread hierarchy
- The GPU’s programming model is organized around logical groupings of execution units called threads.
- From the finest to coarsest level, the thread hierarchy is comprised of threads, warps (32 threads), warpgroups (4 contiguous warps), threadblocks (i.e., cooperative thread arrays or CTAs), threadblock clusters (in Hopper), and grids.
Fused Attention

Flash Attention 1
Paper - https://arxiv.org/pdf/2205.14135
Standard attention in Transformers is slow and memory-hungry because it has quadratic time and memory complexity with sequence length. This becomes a bottleneck for scaling to longer sequences.
Approximate attention methods reduce FLOPs but don’t actually run faster in real time because they ignore I/O bottlenecks—data movement between memory levels in GPUs. On modern GPUs, the compute speed has out-paced memory speed, leaving the bottleneck in IO.
The paper introduces the concept of IO-aware attention, which focuses on minimizing memory reads/writes (not just FLOPs).
“Reference the gpu internals post here”
Types of Memory
| Memory Type | Where It Is | Size | Speed |
|---|---|---|---|
| SRAM (Static RAM) | On-chip (inside the GPU chip) | Tiny (KB–MB) | Fastest |
| HBM (High Bandwidth Memory) | Off-chip but close (next to the GPU chip on the same package found on high performance GPUs) | Medium (~40–80 GB) | Very fast (but slower than SRAM) |
| VRAM (Video RAM) | Off-chip but close (alternative to HBM found on general purpose GPUs | Medium(~16-40GB) | Fast (but slower than HBM) |
| DRAM (Dynamic RAM) | Off-chip, farther (on system motherboard) | Large (GB–TB) | Slowest |
Compute Speed vs. Memory Bandwidth
- Arithmetic throughput of A100: ~19.5 TFLOPs (FP32) & 624 TFLOPs (FP16/BF16)
- This creates a bottleneck: if your model keeps accessing HBM for intermediate values (like the full attention matrix), you end up waiting on memory, not computation.
Many Transformer operations—like softmax, dropout, etc.—are memory-bound, meaning they spend most time waiting on data to move, not computing on it.
The Solution
- Tiling: Breaks large attention computations into small blocks that fit into fast SRAM.
- Recomputation: Instead of storing the huge attention matrix, it recomputes it during the backward pass, using only lightweight statistics saved from the forward pass.
- Kernel Fusion: Fuses multiple attention operations into a single CUDA kernel to avoid repeated memory accesses.
This keeps the memory usage linear in sequence length and significantly reduces wall-clock time.
What Happens in Standard Attention
Let’s take at look at how attention computation would’ve happened without flash attention. For the sake of simiplicity let’s look at just inference.
Consider a QKV shape of \((B, S, H, D) = (1, 4000, 32, 128)\) in bfloat16 on an A100 GPU. Each element would need about 2 bytes and our A100 has a total HBM of 40 GB and SRAM of 100 KB.
Step 1: Matrix Multiply (\(QK^T\))
- The operation \(S = QK^T\) is triggered.
- Since \(Q\) and \(K\) are both huge, they reside in HBM.
- The GPU launches matrix-multiply kernels:
- These kernels stream small chunks (tiles) of Q and K into registers or L1/shared memory (SRAM) temporarily per thread block.
- The GPU never loads the entire Q or K into SRAM at once — it can’t.
- Each small tile of S (say 128×128) is computed and written to HBM.
- This continues until the entire attention matrix S is computed and materialized in HBM.
Step 2: Softmax
- \(S\) is now fully written to HBM.
- Softmax needs each row of \(S\) to compute the normalized probabilities.
- The softmax kernel:
- Reads a row of \(S\) from HBM into registers/SRAM.
- Computes \(softmax(S_{row})\), then
- Writes the result \(P\) back to HBM.
- This repeats for every row → many HBM reads/writes.
Step 3: Multiply P × V
- Now \(P\) (from softmax) and \(V\) are both in HBM.
- The GPU again launches matrix multiply kernels:
- Streams tiles of \(P\) and \(V\) into fast memory,
- Computes output,
- Writes final output \(O\) to HBM.
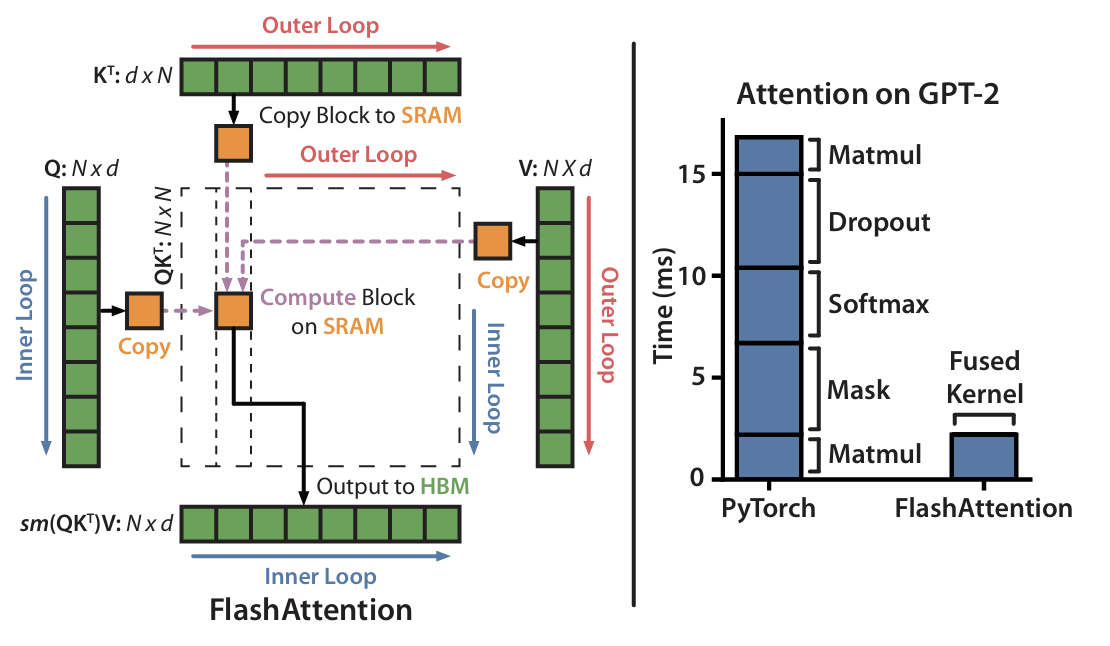
Contrast with FlashAttention
FlashAttention avoids materializing S and P entirely. Instead of writing the full attention matrix S to HBM, it:
- Computes one tile of it (say 128×128),
- Applies softmax to that tile on-the-fly, and
- Immediately multiplies it with a V tile and accumulates the result.
- Nothing is written to HBM except the final output.
Flash Attention 2
Paper - https://arxiv.org/pdf/2307.08691
FlashAttention was fast and memory-efficient, but still underused GPU compute—only 30–50% of peak FLOPs/s on A100. The culprit? Suboptimal parallelism and too many non-matmul operations.
FlashAttention-2 fixes this with algorithmic tuning + better GPU work scheduling, achieving up to 73% of theoretical peak performance. This yields 2-4× wall-clock time speedup over optimized baselines, up to 10-20× memory saving with no approximations.
If you want a quick refresher on threadblocks, warps and threads - You can have a look here
Core Themes
Less Non-Matmul, More Matmul
GPUs are optimized for matmul (tensor core) operations. FlashAttention-2:
- Avoids unnecessary re-scaling and softmax overhead.
- Stores just logsumexp instead of separate
maxandsum—fewer non-matmul FLOPs.
Why it matters: Non-matmul ops are up to 16× slower per FLOP on GPUs.
Finer-Grained Parallelism
FlashAttention used one thread block per head. This works only when \(batchsize × heads\) is large. FlashAttention-2 also parallelizes over sequence length:
- Now each block of rows of the attention matrix gets its own thread block.
- This massively improves GPU occupancy for long sequences + small batches (common in practice).
Smarter Warp Partitioning
Even within a thread block:
- FlashAttention used “split-K” (partition over keys/values), which caused shared memory contention.
- Each warp gets a slice of K/V
- All warps share the same Q block
- Each warp:
- Computes partial \(S_{ij} = Q_iK_{slice}^T\)
- Does \(\exp(S_{ij}) * V_{slice}\)
- Writes its piece of \(O_i\) into shared memory
- Then, warps synchronize and sum partial results
- FlashAttention-2 splits queries (Q) instead → no need for warps to communicate.
Result: fewer syncs, fewer memory reads, better performance.
Algorithm tweaks:
- Delay scaling \(\tilde{O}\) until very end → fewer FLOPs
- Save only \(logsumexp\) instead of both \(max\) and \(sum\)
Execution tweaks:
- Parallelize over sequence blocks, not just heads/batches
- Split Q across warps instead of K/V
Flash Attention 3
FlashAttention-3 is all about fully exploiting Hopper GPUs. While FA2 achieved impressive speedups via IO-awareness and better parallelism, it left performance on the table by:
- Assuming a synchronous execution model
- Ignoring asynchronous execution and low-precision capabilities like FP8
FA3 bridges that gap by integrating hardware-level features:
- 🧵 Warp-specialized asynchrony
- 🧮 Softmax-matmul pipelining
- 🧊 FP8 support
Producer-Consumer Asynchrony (Warp-Specialization)
- Warps are split into producers (load data) and consumers (compute).
- They use a circular shared memory buffer + async barriers to overlap their work.
- This hides data movement latency and register pressure more effectively than in FA2.
Analogy: While one team fills the pipeline, another is already computing — like a relay team that overlaps running and baton-passing.
GEMM–Softmax Overlap (2-Stage Pipelining)
- Matmul (\(QK^T\)) and softmax are interdependent, so normally they serialize.
- FA3 breaks this up into overlapping stages:
- While warpgroup A does \(exp/rowmax\) on \(S_j\),
- Warpgroup B is already doing the next \(QK^T\) for \(S_{j+1}\).
This gets you better utilization of:
- Tensor Cores (GEMM)
- Special function units (exp/log)
GEMM refers to Generalized Matrix Multiplication used synonymous to matrix multiplication operation.

Support for FP8 Quantized Attention
FA3 adds true FP8 support for matmul, nearly doubling throughput by leveraging the FP8 cores present in Hopper GPUs like H100, H200 etc. FP8 has strict memory requirements and as high quantization error owing to its reduced dynamic range.
FA3 addresses these concerns by introducing support for block quantization (per tile instead of tensor) and incoherent processing to “spread out” outliers.
FlashAttention in Practice
FlashAttention-2 (FA2) – PyTorch Ready
📦 Install:
1
pip install flash-attn
You get a PyTorch-compatible module via:
1
2
3
4
5
from flash_attn import flash_attn_func
## Inputs: Q, K, V ∈ [batch, seqlen, nheads, headdim]
## Must be in float16/bfloat16 and contiguous
out = flash_attn_func(q, k, v, dropout_p=0.0, causal=False, softmax_scale=None)
📘 Reference:
FlashAttention-2 GitHub
FlashAttention-3 (FA3)
CUTLASS-based, Hopper GPUs only
⚠️ FA3 is low-level, not yet in PyPI or HuggingFace. You’ll need:
- Hopper GPU (H100)
- CUDA 12.3+
- CUTLASS 3.5
- PyTorch 2.3 (if integrating)
📦 Build FA3 from source:
1
2
3
4
git clone https://github.com/Dao-AILab/flash-attention.git
cd flash-attention
git checkout flashattention-3
pip install -e . # Editable install
🧪 Using FA3:
1
2
3
from flash_attn.flash_attn_interface import flash_attn_func
out = flash_attn_func(q, k, v, dropout_p=0.0, causal=False, softmax_scale=None, return_logsumexp=False)
Ensure your Q/K/V are \((batch, seqlen, nheads, headdim)\),
float16orfp8format, and live on the H100 GPU.
📘 Reference:
FlashAttention-3 GitHub (branch)
What’s next?
FlashAttention isn’t just a speed hack — it’s a rethink of how attention gets done on real hardware. From FA1’s clever memory tiling to FA2’s smarter parallelism to FA3’s full-on GPU wizardry, each version brings us closer to using every ounce of compute on the silicon.
So why does this matter?
Because attention is everywhere — in language models, vision transformers, audio, code, even those 100k-token context length dreams. Faster attention = faster training, cheaper inference, greener AI.
Coming soon (or already here):
- FP8 attention that runs faster than your brain on coffee — with surprising accuracy!
- New low-level alternatives to multi-head attention kernels (cuDNN, Triton, even custom hardware paths).
- If you’re tired of all the theory, I have post coming soon profiling all the drop in attention replacements for inference optimizations.
- Maybe even a day where attention isn’t the bottleneck anymore… but we’ll believe it when we see it.
Until then — flash on. ⚡