
Flash, Fused and Fast Attention
A change of approach From ~2020 onward, the focus of attention research subtly shifted: Before: Researchers were asking, “How can we change the algorithm to avoid quadratic cost?” Thi...
A change of approach From ~2020 onward, the focus of attention research subtly shifted: Before: Researchers were asking, “How can we change the algorithm to avoid quadratic cost?” Thi...
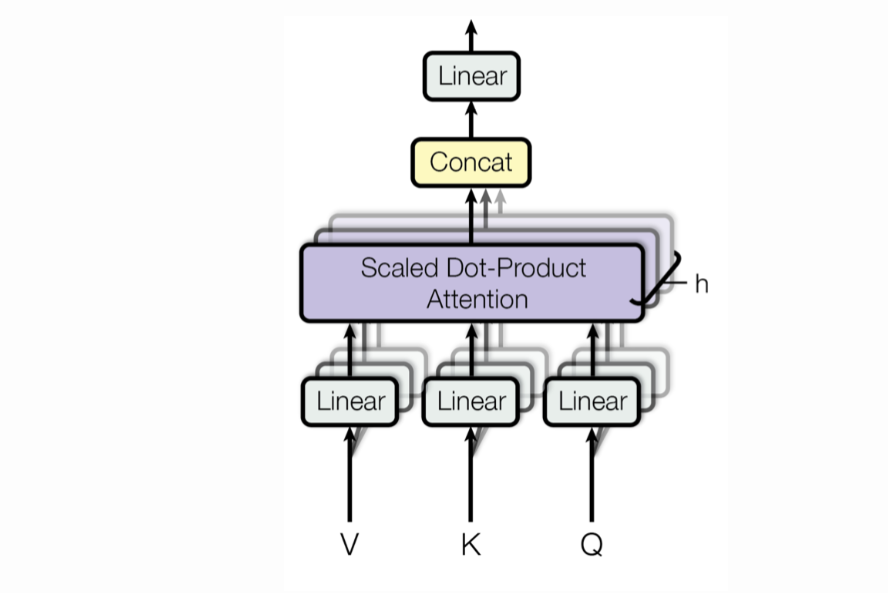
What is Attention? At its core, attention is about figuring out what matters most. In machine learning models, attention helps focus on the most relevant pieces of information when making a decisi...

Coming soon ..

Coming soon …

Extending TensorRT with Custom Plugins TensorRT’s standard operations cover many common use cases, but there are scenarios where custom solutions become necessary: Third-party Integration ...

Coming soon ..
FP8 Quantization with TensorRT Model Optimization Calibration Process Attention Fusion Verification Verify Fusion in Profiler Output
TensorRT in Practice TensorRT promises significant performance improvements for deep learning inference. Though it varies from case to case, I have consistently seen minimum reductions in latency ...

Overview Modern deep learning models require efficient execution to meet production demands. While the core logic of our code defines what we want to achieve, its execution depends on numerous low...
Summary Profile a sample inference pipeline Identify the bottlenecks: CPU vs GPU When we are CPU bound: Eg. Use NeMO GPU dataloader When we are GPU bound: Eg. ?? Ensure overlap of CPU a...